Visualization
WordCloud
![]()
![]()
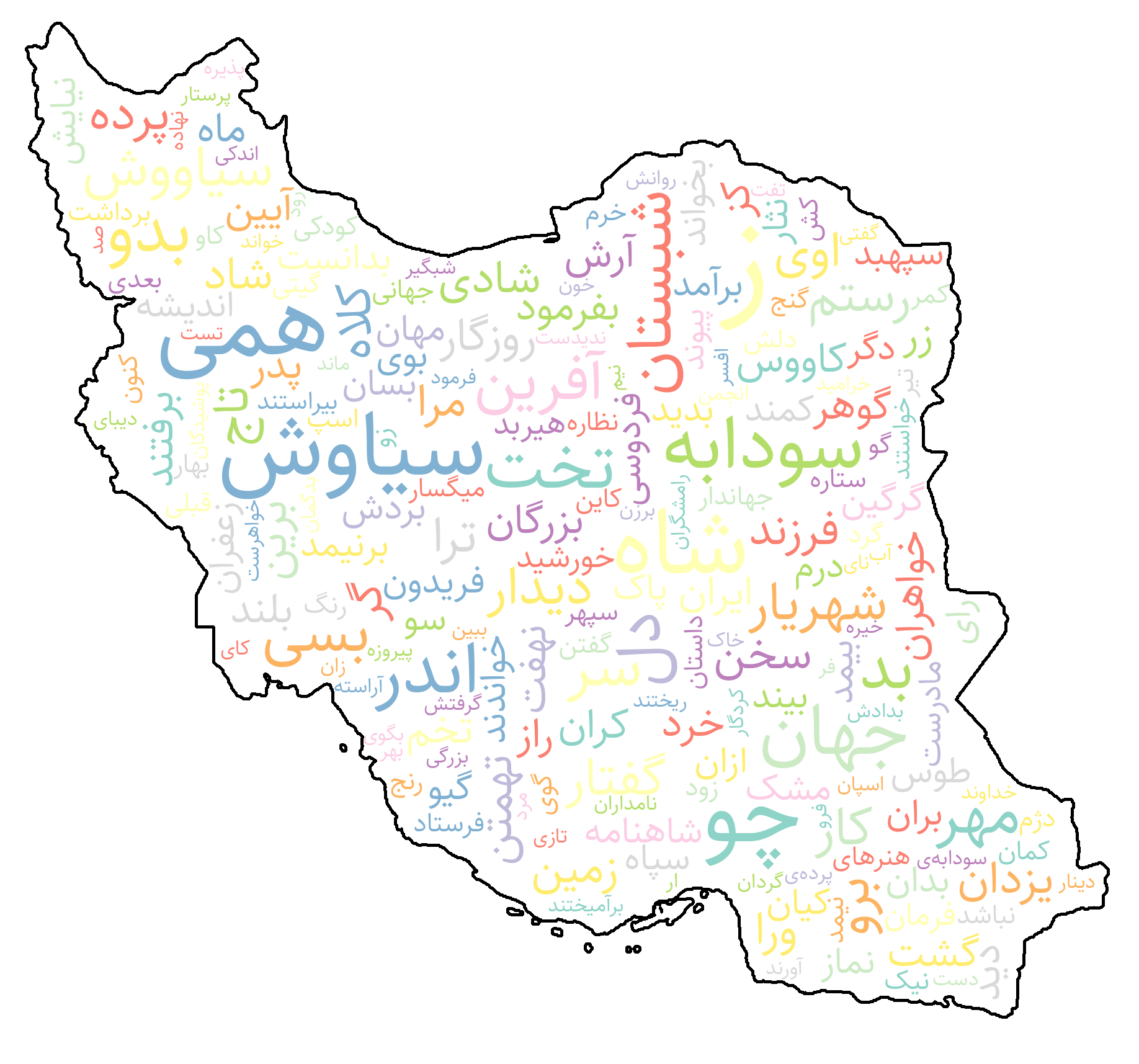
The WordCloud class in Shekar provides a simple and customizable way to generate visually rich Persian word clouds. It supports right-to-left rendering, Persian fonts, custom shape masks, and color maps for elegant and accurate visualization of word frequencies.
Example Usage
import requests
from collections import Counter
from shekar import WordCloud
from shekar import WordTokenizer
from shekar.preprocessing import (
HTMLTagRemover,
PunctuationRemover,
StopWordRemover,
NonPersianRemover,
)
preprocessing_pipeline = HTMLTagRemover() | PunctuationRemover() | StopWordRemover() | NonPersianRemover()
url = f"https://ganjoor.net/ferdousi/shahname/siavosh/sh9"
response = requests.get(url)
html_content = response.text
clean_text = preprocessing_pipeline(html_content)
word_tokenizer = WordTokenizer()
tokens = word_tokenizer(clean_text)
word_freqs = Counter(tokens)
wordCloud = WordCloud(
mask="Iran",
width=1000,
height=500,
max_font_size=220,
min_font_size=5,
bg_color="white",
contour_color="black",
contour_width=3,
color_map="Set2",
)
# if shows disconnect words, try again with bidi_reshape=True
image = wordCloud.generate(word_freqs, bidi_reshape=False)
image.show()