بصریسازی
ابرواژه (WordCloud)
![]()
![]()
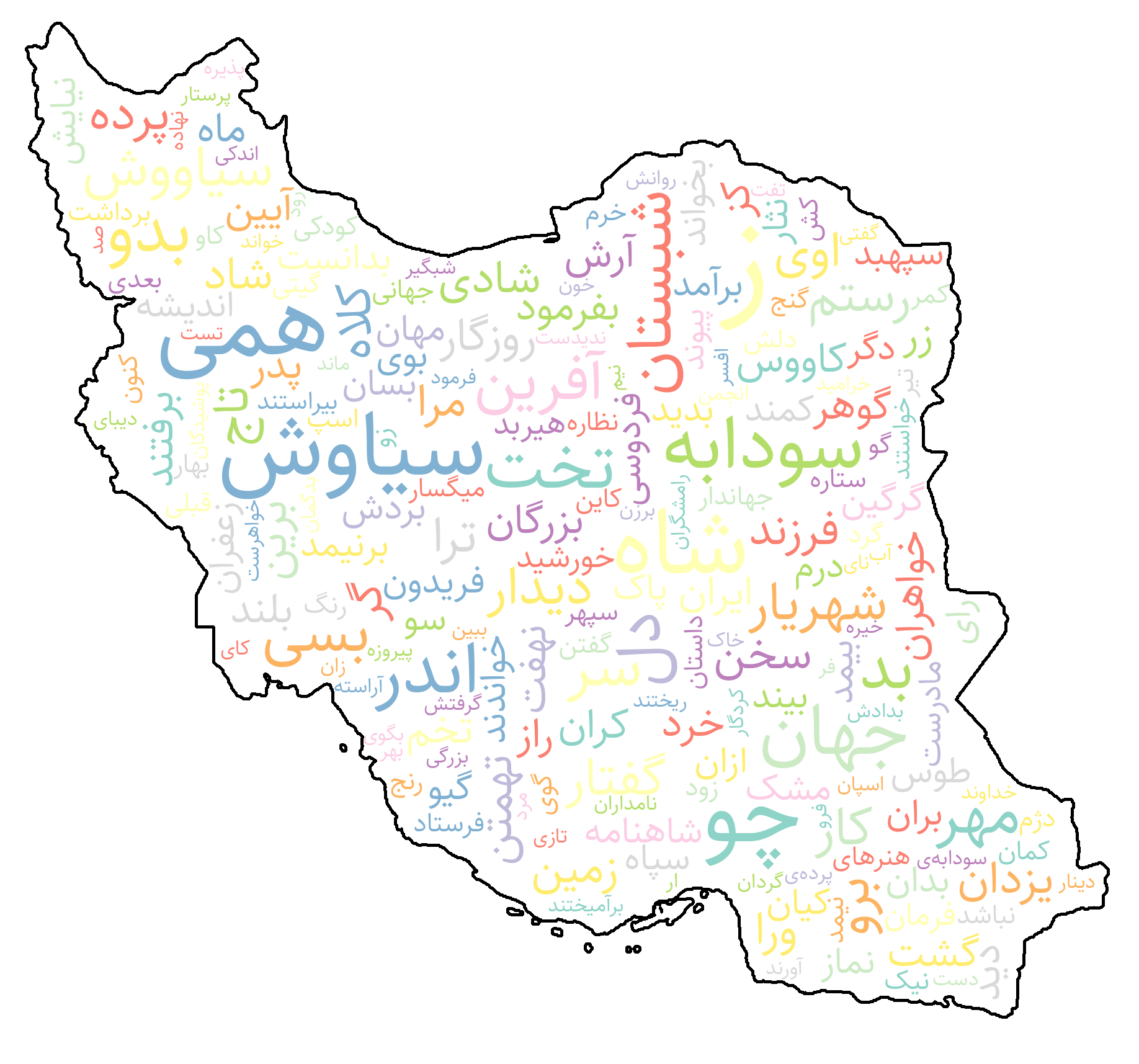
کلاس WordCloud در Shekar راهی ساده و قابلسفارشیسازی برای تولید ابرواژهٔ فارسی فراهم میکند. این کلاس از نمایش راستبهچپ، فونتهای فارسی، ماسکهای شکل سفارشی و نقشههای رنگ پشتیبانی میکند تا نمایش دقیق و زیبایی از فراوانی واژهها ایجاد شود.
نمونهٔ استفاده
import requests
from collections import Counter
from shekar import WordCloud
from shekar import WordTokenizer
from shekar.preprocessing import (
HTMLTagRemover,
PunctuationRemover,
StopWordRemover,
NonPersianRemover,
)
preprocessing_pipeline = HTMLTagRemover() | PunctuationRemover() | StopWordRemover() | NonPersianRemover()
url = f"https://ganjoor.net/ferdousi/shahname/siavosh/sh9"
response = requests.get(url)
html_content = response.text
clean_text = preprocessing_pipeline(html_content)
word_tokenizer = WordTokenizer()
tokens = word_tokenizer(clean_text)
word_freqs = Counter(tokens)
wordCloud = WordCloud(
mask="Iran",
width=1000,
height=500,
max_font_size=220,
min_font_size=5,
bg_color="white",
contour_color="black",
contour_width=3,
color_map="Set2",
)
# اگر واژهها جدا دیده شدند، با bidi_reshape=True دوباره اجرا کنید
image = wordCloud.generate(word_freqs, bidi_reshape=False)
image.show()