بازنماییها (Embeddings)
![]()
![]()
بازنماییها، نمایش عددی متن هستند که معنا و شباهت معنایی را کد میکنند. از آنها در کارهایی مثل خوشهبندی، جستوجوی معنایی و طبقهبندی استفاده میشود. Shekar دو کلاس اصلی برای بازنمایی واژه و جمله با رابط کاربری یکسان ارائه میدهد.
ویژگیهای کلیدی
- رابط یکپارچه: هر دو کلاس متدهای
embed()وtransform()را ارائه میکنند. - ایستا و زمینهمند: انتخاب بین بازنمایی ایستای مبتنی بر FastText یا بازنمایی زمینهمند مبتنی بر ALBERT.
- سازگار با NumPy: خروجی مستقیم بهصورت بردار NumPy برای ادغام آسان.
بازنمایی واژه
کلاس WordEmbedder بازنماییهای ایستای واژه را با مدلهای از پیشآموزشدیدهٔ FastText فراهم میکند.
مدلهای موجود
fasttext-d100: مدل CBOW با بُعد 100 آموزشدیده روی ویکیپدیای فارسی.fasttext-d300: مدل CBOW با بُعد 300 آموزشدیده روی دیتاست بزرگ Naab.
نکته: این بازنماییها ایستا و از پیش محاسبهشده هستند تا پایداری بیشتر داشته باشند؛ چون وابستگیهای Gensim در نسخههای جدید بهروز نیستند.
نمونهٔ استفاده
from shekar.embeddings import WordEmbedder
# بارگذاری مدل FastText با بُعد 100
embedder = WordEmbedder(model="fasttext-d100")
# دریافت بردار یک واژه
embedding = embedder("کتاب")
print(embedding.shape) # (100,)
# یافتن واژههای مشابه
similar_words = embedder.most_similar("کتاب", top_n=5)
print(similar_words)
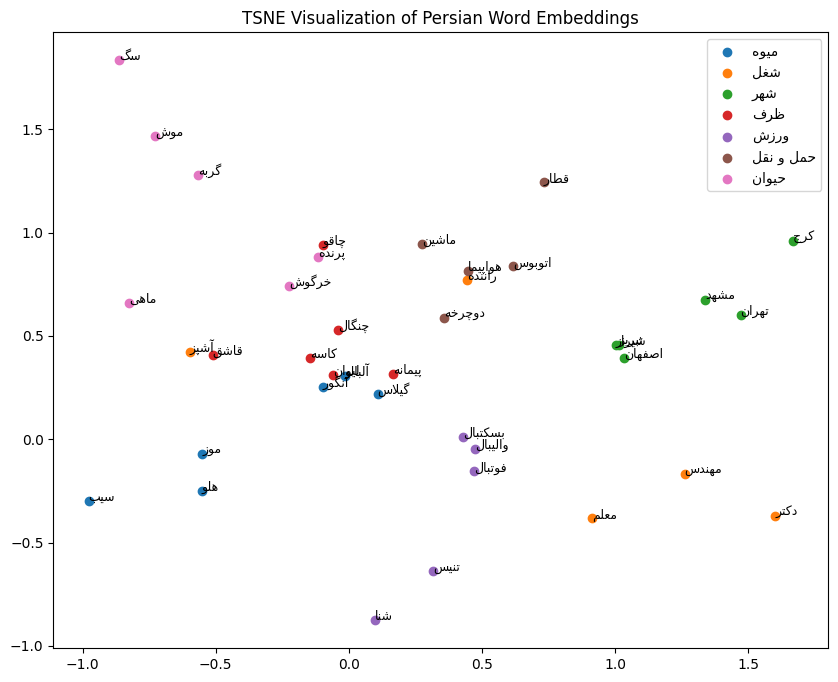
from sklearn.manifold import TSNE
import numpy as np
import matplotlib.pyplot as plt
import arabic_reshaper
from bidi.algorithm import get_display
def fix_persian(text: str) -> str:
return get_display(arabic_reshaper.reshape(text))
# دستهها
categories = {
"میوه": ["سیب", "موز", "انگور", "هلو", "آلبالو", "گیلاس", "توت فرنگی"],
"شغل": ["برنامه نویس", "مهندس", "دکتر", "معلم", "راننده", "آشپز"],
"شهر": ["تهران", "اصفهان", "شیراز", "مشهد", "تبریز", "کرج"],
"ظرف": ["قاشق", "چنگال", "چاقو", "لیوان", "کاسه", "پیمانه"],
"ورزش": ["فوتبال", "بسکتبال", "والیبال", "تنیس", "شنا", "دوچرخه سواری"],
"حمل و نقل": ["ماشین", "اتوبوس", "قطار", "هواپیما", "دوچرخه", "موتور سیکلت"],
"حیوان": ["گربه", "سگ", "پرنده", "ماهی", "خرگوش", "موش"],
}
words, labels = [], []
for cat, items in categories.items():
words.extend(items)
labels.extend([cat] * len(items))
in_vocab_words, in_vocab_labels, embeddings = [], [], []
for word, label in zip(words, labels):
vec = embbeder(word)
if vec is not None:
embeddings.append(vec)
in_vocab_words.append(word)
in_vocab_labels.append(label)
embeddings = np.vstack(embeddings)
tsne = TSNE(n_components=2, random_state=42, init="pca", learning_rate="auto")
embeddings_2d = tsne.fit_transform(embeddings)
plt.figure(figsize=(10, 8))
for cat in categories:
idx = [i for i, label in enumerate(in_vocab_labels) if label == cat]
if not idx:
continue
plt.scatter(embeddings_2d[idx, 0], embeddings_2d[idx, 1], label=fix_persian(cat))
for i in idx:
plt.text(
embeddings_2d[i, 0],
embeddings_2d[i, 1],
fix_persian(in_vocab_words[i]),
fontsize=9,
)
plt.legend()
plt.title("TSNE Visualization of Persian Word Embeddings")
plt.show()
بازنمایی زمینهمند
کلاس SentenceEmbedder از یک مدل ALBERT ریزتنظیمشده با هدف Masked Language Modeling (MLM) روی دیتاست Naab استفاده میکند تا برای عبارتها یا جملهها، بازنمایی زمینهمند بسازد.
- اندازهٔ بردار: 768 بُعد
- زمینهمند: درک معنای واژهها با توجه به بافت اطراف
نمونهٔ استفاده