مرور کلی






سادهسازی پردازش زبان فارسی برای کاربردهای نوین
فهرست مطالب
- راهاندازی
- نصب نسخهٔ CPU (سازگار با همهٔ پلتفرمها)
- اجرای شتابیافته با کارت گرافیک
- پیشپردازش
- یکنواختسازی متن
- پردازش دستهای
- پشتیبانی از دکوراتور
- سفارشیسازی
- بهرهگیری از زنجیرههای پردازش
- بخشبندی متن
- بخشبندی واژگانی
- بخشبندی جملهای
- (Embeddings) بازنماییها
- بازنمایی واژگانی
- بازنمایی جملهای
- ریشهیابی سطحی
- ریشهیابی بنیادی
- برچسبگذاری نقشهای دستوری
- شناسایی موجودیتهای نامدار
- واکاوی وابستگی دستوری
- سنجش احساسات
- کلیدواژهیابی
- غلطیابی املایی
- ابر واژگان
- رابط وب
- بارگیری مدلها
راهاندازی
جهت نصب کتابخانهٔ شکر، ابتدا لازم است اطمینان حاصل کنید که Python و pip بر روی سیستم شما نصب شده باشند. سپس ترمینال یا خط فرمان را باز کرده و دستور زیر را اجرا نمایید. با این کار، بسته از مخزن PyPI دریافت و بر روی سیستم شما نصب خواهد شد. پس از تکمیل فرآیند نصب، میتوانید از قابلیتهای کتابخانه در پروژههای پردازش زبان فارسی استفاده کنید.
به صورت پیشفرض، مدلهای زبانی شِکَر با استفاده از CPU اجرا میشوند و روی همهٔ سیستمها بهدرستی عمل میکنند.
نصب نسخهٔ CPU (سازگار با همهٔ پلتفرمها)
این روش روی Windows، Linux و macOS (شامل تراشههای Apple Silicon مانند M1/M2/M3) کار میکند.
اجرای شتابیافته با کارت گرافیک
اگر کارت گرافیک NVIDIA دارید و میخواهید از قدرت پردازشی GPU برای سرعت بیشتر استفاده کنید، نیاز دارید که نسخه CPU را حذف کرده و نسخه GPU را نصب کنید.
پیشنیازها
- کارت گرافیک NVIDIA با پشتیبانی CUDA
- نصب CUDA Toolkit مناسب
- درایورهای سازگار NVIDIA
پیشپردازش
![]()
![]()
یکنواختسازی متن
کلاس داخلی Normalizer یک زنجیرهٔ پردازش آماده ارائه میدهد که پرکاربردترین فیلترها و مراحل یکنواختسازی را در هم میآمیزد. این تنظیمات پیشفرض بهگونهای طراحی شدهاند که بیشترِ کاربردهای رایج را پوشش دهند.
from shekar import Normalizer
normalizer = Normalizer()
text = "«فارسی شِکَر است » نام داستان ڪوتاه طنز آمێزی از محمد علی جمالــــــــزاده ی گرامی می باشد که در سال 1921 منتشر شدهاست و آغاز ڱر تحول بزرگی در ادَبێات معاصر ایران بۃ شمار میرود."
print(normalizer(text))
# نرمالسازی نویسههای گفتاری و روزمره
text = normalizer("تا آخر هفته بر میگردم ولی نمیرم خونه بابا اینا. اونم اگه خواست میتونه بیاد خونه مون بمونه .")
print(text)
# نرمالسازی واژههای مرکب و افعال پیشوندی!
text = normalizer("یک کار آفرین نمونه و سخت کوش ، پیروز مندانه از پس دشواری ها برخواهدآمد.")
print(text)
«فارسی شکر است» نام داستان کوتاه طنزآمیزی از محمدعلی جمالزادهی گرامی میباشد که در سال ۱۹۲۱ منتشر شده است و آغازگر تحول بزرگی در ادبیات معاصر ایران به شمار میرود.
تا آخر هفته برمیگردم ولی نمیرم خونه بابا اینا. اونم اگه خواست میتونه بیاد خونهمون بمونه.
یک کارآفرین نمونه و سختکوش، پیروزمندانه از پس دشواریها بر خواهد آمد.
پردازش دستهای
هر دو کلاس Normalizer و Pipeline از پردازش دستهای (Batch Processing) با کارایی بالای حافظه پشتیبانی میکنند.
texts = [
"پرندههای 🐔 قفسی، عادت دارن به بیکسی!",
"تو را من چشم👀 در راهم!"
]
outputs = normalizer.fit_transform(texts)
print(list(outputs))
پشتیبانی از دکوراتور
جهت بهکارگیری زنجیرهٔ پردازش روی ورودیهای مشخص یک تابع، میتوانید از on_args(...) بهره بگیرید.
@normalizer.on_args(["text"])
def process_text(text):
return text
print(process_text("تو را من چشم👀 در راهم!"))
سفارشیسازی
برای سفارشیسازی پیشرفته، کتابخانهٔ شِکَر یک چارچوب ماژولار و ترکیبپذیر برای پیشپردازش متن ارائه میدهد. این چارچوب شامل مؤلفههایی مانند normalizers و maskers است که میتوانند بهصورت مستقل بهکار گرفته شوند یا با استفاده از کلاس Pipeline و عملگر | بهطور انعطافپذیر با یکدیگر ترکیب شوند.
نمای کلی اجزا
یکنواختسازها (Normalizers)
| مؤلفه | نامهای دیگر | شرح |
|---|---|---|
AlphabetNormalizer |
NormalizeAlphabets |
نویسههای عربی را به معادل فارسی آنها تبدیل میکند. |
ArabicUnicodeNormalizer |
NormalizeArabicUnicodes |
شکلهای نمایشی عربی (مانند ﷽) را با نویسههای فارسی جایگزین میکند. |
DigitNormalizer |
NormalizeDigits |
اعداد انگلیسی و عربی را به اعداد فارسی تبدیل میکند. |
PunctuationNormalizer |
NormalizePunctuations |
علائم سجاوندی را یکدست و استانداردسازی میکند. |
RepeatedLetterNormalizer |
NormalizeRepeatedLetters |
حروف تکرارشده را به صورت استاندارد در میآورد (مانند «سسسلام» → «سلام»). |
SpacingNormalizer |
NormalizeSpacings |
فاصلهگذاری را در متن فارسی اصلاح میکند؛ از جمله خطاهایی مانند نبود نیمفاصله (ZWNJ) یا فاصلهگذاری نادرست پیرامون علائم و پسوندها. |
YaNormalizer |
NormalizeYas |
نویسهٔ «ی» را مطابق با شیوهٔ نگارش رسمی («standard») یا محاورهای («joda») یکدست میکند. |
پوشانندهها (Maskers)
| مؤلفه | نامهای دیگر | شرح |
|---|---|---|
DiacriticMasker |
DiacriticRemover, RemoveDiacritics, MaskDiacritics |
نشانههای حرکتی (اعراب) در متون فارسی/عربی را حذف یا پنهان میکند. |
DigitMasker |
DigitRemover, RemoveDigits, MaskDigits |
نویسههای عددی را حذف یا با نشانهٔ پوششی جایگزین میکند. |
EmojiMasker |
EmojiRemover, RemoveEmojis, MaskEmojis |
ایموجیها را از متن حذف یا پنهان میکند. |
EmailMasker |
EmailRemover, RemoveEmails, MaskEmails |
نشانیهای ایمیل را پوشانده یا حذف میکند. |
HashtagMasker |
HashtagRemover, RemoveHashtags, MaskHashtags |
هشتگها را حذف یا با نشانهٔ پوششی جایگزین میکند. |
HTMLTagMasker |
HTMLTagRemover, RemoveHTMLTags, MaskHTMLTags |
برچسبهای HTML را حذف کرده و محتوای متن را نگه میدارد. |
MentionMasker |
MentionRemover, RemoveMentions, MaskMentions |
اشارههای کاربری (@mention) را حذف یا پنهان میکند. |
NonPersianLetterMasker |
NonPersianRemover, RemoveNonPersianLetters, MaskNonPersianLetters |
نویسههای غیرفارسی را حذف یا پنهان میکند (در صورت نیاز، نویسههای انگلیسی را حفظ میکند). |
OffensiveWordMasker |
OffensiveWordRemover, RemoveOffensiveWords, MaskOffensiveWords |
واژههای ناشایست یا نامناسب فارسی را شناسایی و حذف یا پنهان میکند. |
PunctuationMasker |
PunctuationRemover, RemovePunctuations, MaskPunctuations |
نشانههای سجاوندی را حذف یا پنهان میکند. |
StopWordMasker |
StopWordRemover, RemoveStopWords, MaskStopWords |
ایستواژههای پرتکرار را از متن حذف یا پنهان میکند. |
URLMasker |
URLRemover, RemoveURLs, MaskURLs |
نشانیهای اینترنتی (URL) را حذف یا پنهان میکند. |
بهرهگیری از زنجیرههای پردازش
میتوانید هر یک از اجزای پیشپردازش را با استفاده از عملگر | با یکدیگر ترکیب کنید.
from shekar.preprocessing import EmojiRemover, PunctuationRemover
text = "ز ایران دلش یاد کرد و بسوخت! 🌍🇮🇷"
pipeline = EmojiRemover() | PunctuationRemover()
output = pipeline(text)
print(output)
بخشبندی متن
بخشبندی واژگانی
کلاس WordTokenizer در کتابخانهٔ شِکَر یک بخشبند واژگانی مبتنی بر قواعد برای زبان فارسی است که با تکیه بر عبارتهای منظم سازگار با یونیکد، متن را بر اساس علائم سجاوندی و فاصلهها تفکیک مینماید.
from shekar import WordTokenizer
tokenizer = WordTokenizer()
text = "چه سیبهای قشنگی! حیات نشئهٔ تنهایی است."
tokens = list(tokenizer(text))
print(tokens)
بخشبندی جملهای
کلاس SentenceTokenizer برای بخشبندی یک متن به جملات جداگانه طراحی شده است. این کلاس بهویژه در وظایف پردازش زبان طبیعی که در آنها درک ساختار و معنای جمله اهمیت دارد، بسیار کاربردی است.
SentenceTokenizer قادر است با در نظر گرفتن علائم نگارشی گوناگون و قواعد خاص زبان، مرز میان جملات را بهطور دقیق تشخیص دهد.
from shekar.tokenizers import SentenceTokenizer
text = "هدف ما کمک به یکدیگر است! ما میتوانیم با هم کار کنیم."
tokenizer = SentenceTokenizer()
sentences = tokenizer(text)
for sentence in sentences:
print(sentence)
(Embeddings) بازنماییها
![]()
![]()
کتابخانهٔ شکر دو کلاس اصلی برای بازنمایی (Embedding) ارائه میدهد:
WordEmbedder: بازنمایی ایستای واژهها با استفاده از مدلهای از پیش آموزشدیدهٔ FastText.
SentenceEmbedder: بازنمایی متنی با استفاده از مدل ALBERT.
هر دو کلاس یک رابط کاربری یکسان دارند:
متد embed(text) یک بردار NumPy برمیگرداند.
متد transform(text) نام مستعاری برای embed(text) است تا بتوان آن را بهراحتی در زنجیرههای پردازش بهکار گرفت.
بازنمایی واژگانی
کلاس WordEmbedder از دو مدل ایستای FastText پشتیبانی میکند:
-
fasttext-d100: مدل CBOW با ابعاد ۱۰۰ که بر اساس پیکرهٔ ویکیپدیای فارسی آموزش یافته است. -
fasttext-d300: مدل CBOW با ابعاد ۳۰۰ که بر اساس پیکرهٔ ناب آموزش یافته است.
توجه: تعبیههای واژهای در شِکَر بهصورت آماده و ایستا ذخیره شدهاند. دلیل این کار مشکلات سازگاری نسخههای قدیمی کتابخانهٔ Gensim است. با ذخیرهسازی بردارهای از پیش محاسبهشده، پایداری و کارکرد مطمئن کتابخانه تضمین میشود.
from shekar.embeddings import WordEmbedder
embedder = WordEmbedder(model="fasttext-d100")
embedding = embedder("کتاب")
print(embedding.shape)
similar_words = embedder.most_similar("کتاب", top_n=5)
print(similar_words)
بازنمایی جملهای
کلاس SentenceEmbedder از یک مدل ALBERT بهره میگیرد که با روش Masked Language Modeling (MLM) بر روی پیکرهٔ ناب آموزش دیده است تا تعبیههای متنی باکیفیت و وابسته به زمینه تولید کند. خروجی این مدل بردارهایی با ۷۶۸ بُعد هستند که معنای واژگانی و مفهومی کل عبارات یا جملات را بازنمایی میکنند.
from shekar.embeddings import SentenceEmbedder
embedder = SentenceEmbedder(model="albert")
sentence = "کتابها دریچهای به جهان دانش هستند."
embedding = embedder(sentence)
print(embedding.shape) # (768,)
ریشهیابی سطحی
کلاس Stemmer یک ریشهیاب سبک و مبتنی بر قواعد برای زبان فارسی است. این ابزار پسوندهای رایج را حذف میکند، در حالی که به قواعد خط فارسی و استفاده از نیمفاصله (ZWNJ) پایبند میماند. هدف آن تولید ریشههای پایدار برای جستجو، نمایهسازی و تحلیل سادهٔ متن است، بدون آنکه نیاز به یک تحلیلگر کامل صرفی داشته باشد.
from shekar import Stemmer
stemmer = Stemmer()
print(stemmer("نوهام"))
print(stemmer("کتابها"))
print(stemmer("خانههایی"))
print(stemmer("خونههامون"))
ریشهیابی بنیادی
کلاس Lemmatizer واژههای فارسی را به صورت پایه و فرهنگنامهای آنها نگاشت میکند. بر خلاف ریشهیابی سطحی که تنها پسوندها را حذف میکند، ریشهیابی پایهای از قواعد صرف فعل، جستوجو در واژگان، و ریشهیاب پشتیبان بهره میگیرد تا ریشه معتبر تولید کند. این ویژگی باعث میشود در کارهایی مانند برچسبگذاری نقشهای دستوری (POS tagging)، نرمالسازی متن، و تحلیلهای زبانی که نیاز به شکل معیار واژه دارند، دقت بیشتری حاصل شود.
from shekar import Lemmatizer
lemmatizer = Lemmatizer()
print(lemmatizer("رفتند"))
print(lemmatizer("کتابها"))
print(lemmatizer("خانههایی"))
print(lemmatizer("گفته بودهایم"))
برچسبگذاری نقشهای دستوری
![]()
![]()
کلاس POSTagger برچسبگذاری نقشهای دستوری را برای متون فارسی با استفاده از یک مدل مبتنی بر Transformer (پیشفرض: ALBERT) انجام میدهد. این کلاس برای هر واژه یک برچسب بر اساس دستهبندیهای جهانی نقشهای دستوری (Universal POS tags) و مطابق با استاندارد Universal Dependencies بازمیگرداند.
نمونه کد:
from shekar import POSTagger
pos_tagger = POSTagger()
text = "نوروز، جشن سال نو ایرانی، بیش از سه هزار سال قدمت دارد و در کشورهای مختلف جشن گرفته میشود."
result = pos_tagger(text)
for word, tag in result:
print(f"{word}: {tag}")
نوروز: PROPN
،: PUNCT
جشن: NOUN
سال: NOUN
نو: ADJ
ایرانی: ADJ
،: PUNCT
بیش: ADJ
از: ADP
سه: NUM
هزار: NUM
سال: NOUN
قدمت: NOUN
دارد: VERB
و: CCONJ
در: ADP
کشورهای: NOUN
مختلف: ADJ
جشن: NOUN
گرفته: VERB
میشود: VERB
.: PUNCT
شناسایی موجودیتهای نامدار
![]()
![]()
ماژول NER در شِکَر یک زنجیرهٔ پردازش سریع برای شناسایی موجودیتهای نامدار فراهم میکند که بر پایهٔ مدل ALBERT در قالب ONNX پیادهسازی شده است. این ماژول موجودیتهای رایج در زبان فارسی مانند افراد، مکانها، سازمانها و تاریخها را شناسایی میکند.
این مدل برای استنتاج کارآمد طراحی شده و بهسادگی میتواند با سایر مراحل پیشپردازش متن ترکیب شود.
نمونه کد:
from shekar import NER
from shekar import Normalizer
input_text = (
"شاهرخ مسکوب به سالِ ۱۳۰۴ در بابل زاده شد و دوره ابتدایی را در تهران و در مدرسه علمیه پشت "
"مسجد سپهسالار گذراند. از کلاس پنجم ابتدایی مطالعه رمان و آثار ادبی را شروع کرد. از همان زمان "
"در دبیرستان ادب اصفهان ادامه تحصیل داد. پس از پایان تحصیلات دبیرستان در سال ۱۳۲۴ از اصفهان به تهران رفت و "
"در رشته حقوق دانشگاه تهران مشغول به تحصیل شد."
)
normalizer = Normalizer()
normalized_text = normalizer(input_text)
albert_ner = NER()
entities = albert_ner(normalized_text)
for text, label in entities:
print(f"{text} → {label}")
شاهرخ مسکوب → PER
سال ۱۳۰۴ → DAT
بابل → LOC
دوره ابتدایی → DAT
تهران → LOC
مدرسه علمیه → LOC
مسجد سپهسالار → LOC
دبیرستان ادب اصفهان → LOC
در سال ۱۳۲۴ → DAT
اصفهان → LOC
تهران → LOC
دانشگاه تهران → ORG
فرانسه → LOC
میتوانید ماژول NER را بهسادگی با سایر اجزا از طریق عملگر | زنجیره کنید.
ner_pipeline = normalizer | albert_ner
entities = ner_pipeline(input_text)
for text, label in entities:
print(f"{text} → {label}")
این زنجیرهسازی کدی تمیز و خوانا فراهم میکند و به شما امکان میدهد زنجیرههای NLP سفارشی بسازید که در یک مرحله شامل پیشپردازش و برچسبگذاری باشند.
واکاوی وابستگی دستوری
کلاس DependencyParser واکاوی وابستگی دستوری متن فارسی را با استفاده از یک مدل مبتنی بر Transformer (پیشفرض: ALBERT) انجام میدهد. این کلاس ساختار دستوری گزاره را واکاوی کرده و برای هر واژه، سرواژهٔ نحوی آن (با شمارهگذاری از ۱، که ۰ به معنای ROOT است) و برچسب رابطهٔ وابستگی را براساس استاندارد Universal Dependencies برمیگرداند.
نمونه کد:
from shekar import DependencyParser
parser = DependencyParser()
text = "ما با آنچه میسازیم ایرانی هستیم."
result = parser(text)
for word, head, deprel in result:
print(f"{word} ← (head: {head}, relation: {deprel})")
ما ← (head: 6, relation: nsubj)
با ← (head: 3, relation: case)
آنچه ← (head: 6, relation: obl)
میسازیم ← (head: 3, relation: acl)
ایرانی ← (head: 6, relation: xcomp)
هستیم ← (head: 0, relation: root)
. ← (head: 6, relation: punct)
میتوانید نتیجهٔ تحلیل را به صورت درخت با متد print_tree() نمایش دهید:
ROOT
└── [root] هستیم
├── [nsubj] ما
├── [obl] آنچه
│ ├── [case] با
│ └── [acl] میسازیم
├── [xcomp] ایرانی
└── [punct] .
سنجش احساسات
ماژول SentimentClassifier امکان واکاوی خودکار احساسات در متون فارسی را با استفاده از مدلهای مبتنی بر مدلهای زبانی فراهم میکند. در حال حاضر از مدل AlbertBinarySentimentClassifier پشتیبانی میکند، مدلی سبک بر پایهٔ ALBERT که بر روی دادگان Snapfood آموزش دیده و نوشته را به دو دستهٔ مثبت یا منفی طبقهبندی میکند و علاوه بر برچسب پیشبینیشده، امتیاز اطمینان آن را نیز برمیگرداند.
نمونه کد:
from shekar import SentimentClassifier
sentiment_classifier = SentimentClassifier()
print(sentiment_classifier("سریال قصههای مجید عالی بود!"))
print(sentiment_classifier("فیلم ۳۰۰ افتضاح بود!"))
کلیدواژهیابی
![]()
![]()
کلاس KeywordExtractor ابزارهایی برای شناسایی و استخراج خودکار اصطلاحات و عبارات کلیدی از متون فارسی فراهم میکند. این الگوریتمها به شناسایی مهمترین مفاهیم و موضوعات موجود در اسناد کمک میکنند.
from shekar import KeywordExtractor
extractor = KeywordExtractor(max_length=2, top_n=10)
input_text = (
"زبان فارسی یکی از زبانهای مهم منطقه و جهان است که تاریخچهای کهن دارد. "
"زبان فارسی با داشتن ادبیاتی غنی و شاعرانی برجسته، نقشی بیبدیل در گسترش فرهنگ ایرانی ایفا کرده است. "
"از دوران فردوسی و شاهنامه تا دوران معاصر، زبان فارسی همواره ابزار بیان اندیشه، احساس و هنر بوده است. "
)
keywords = extractor(input_text)
for kw in keywords:
print(kw)
غلطیابی املایی
کلاس SpellChecker امکان تصحیح ساده و کارآمد غلطهای املایی در متون فارسی را فراهم میکند. این کلاس میتواند بهطور خودکار خطاهای رایج مانند حروف اضافه، اشتباهات فاصلهگذاری و واژههای نادرست را شناسایی و اصلاح کند. میتوانید آن را بهصورت مستقیم روی یک جمله به کار ببرید تا متن اصلاح شود، یا با متد suggest() فهرستی رتبهبندیشده از پیشنهادهای اصلاح برای یک واژه دریافت کنید.
from shekar import SpellChecker
spell_checker = SpellChecker()
print(spell_checker("سسلام بر ششما ددوست من"))
print(spell_checker.suggest("درود"))
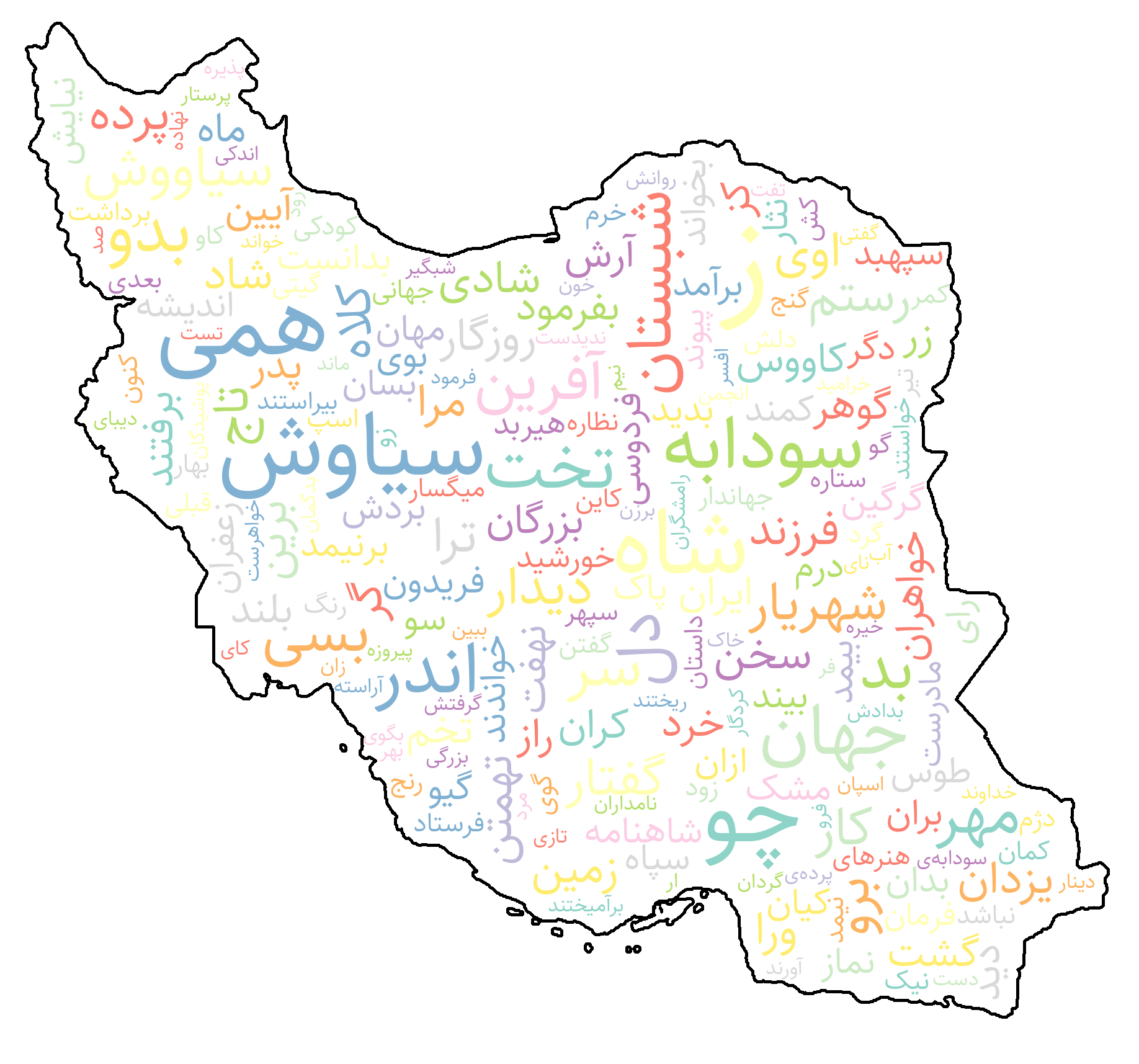
ابر واژگان
![]()
![]()
کلاس WordCloud راهی ساده برای ساخت ابر واژگان فارسی با جلوههای بصری غنی فراهم میکند. این کلاس از نمایش راستبهچپ پشتیبانی میکند و امکان استفاده از فونتهای فارسی، نقشههای رنگی (colormaps) و شکلهای سفارشی را فراهم میسازد تا فراوانی واژهها بهصورت دقیق و زیبا بصریسازی شود.
import requests
from collections import Counter
from shekar import WordCloud
from shekar import WordTokenizer
from shekar.preprocessing import (
HTMLTagRemover,
PunctuationRemover,
StopWordRemover,
NonPersianRemover,
)
preprocessing_pipeline = HTMLTagRemover() | PunctuationRemover() | StopWordRemover() | NonPersianRemover()
url = f"https://ganjoor.net/ferdousi/shahname/siavosh/sh9"
response = requests.get(url)
html_content = response.text
clean_text = preprocessing_pipeline(html_content)
word_tokenizer = WordTokenizer()
tokens = word_tokenizer(clean_text)
word_freqs = Counter(tokens)
wordCloud = WordCloud(
mask="Iran",
width=1000,
height=500,
max_font_size=220,
min_font_size=5,
bg_color="white",
contour_color="black",
contour_width=3,
color_map="Set2",
)
# if shows disconnect words, try again with bidi_reshape=True
image = wordCloud.generate(word_freqs, bidi_reshape=False)
image.show()
رابط وب
کتابخانهٔ شکر یک رابط وب داخلی دارد که به شما امکان میدهد قابلیتهای پردازش زبان فارسی را بهصورت تعاملی کاوش کنید؛ بدون نیاز به نوشتن حتی یک خط کد. کافی است با یک دستور ساده آن را راهاندازی کنید:
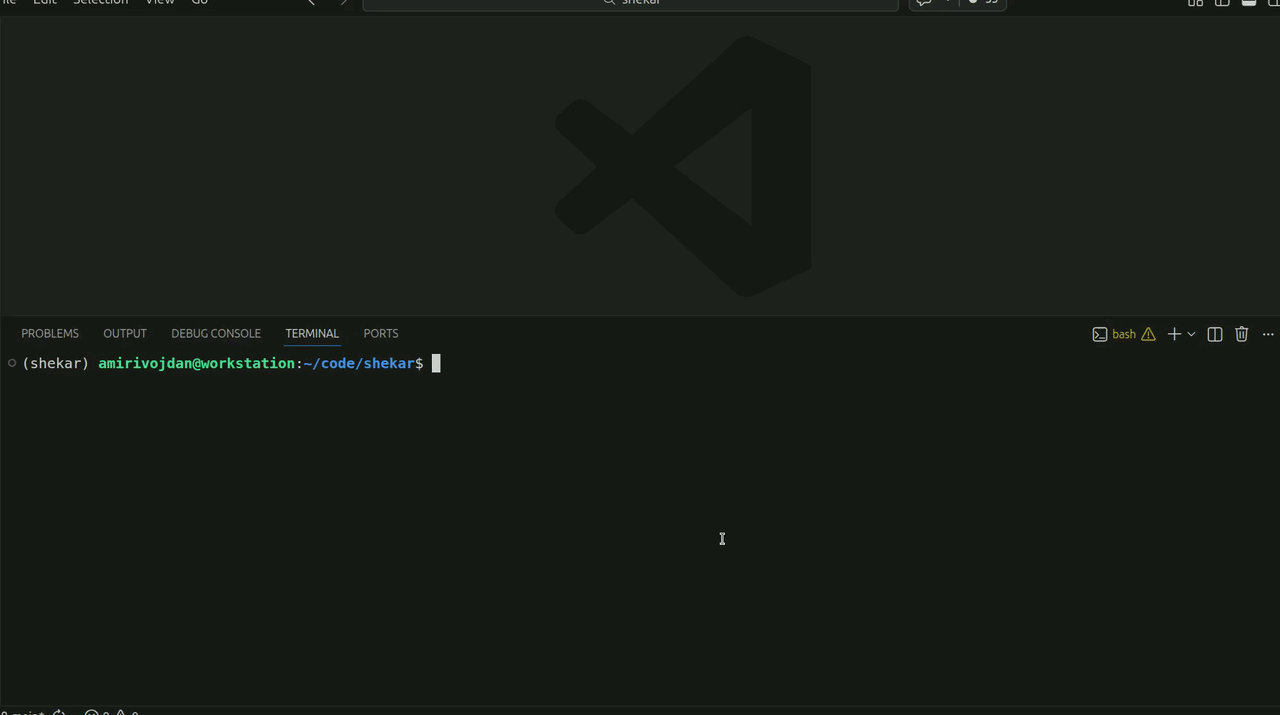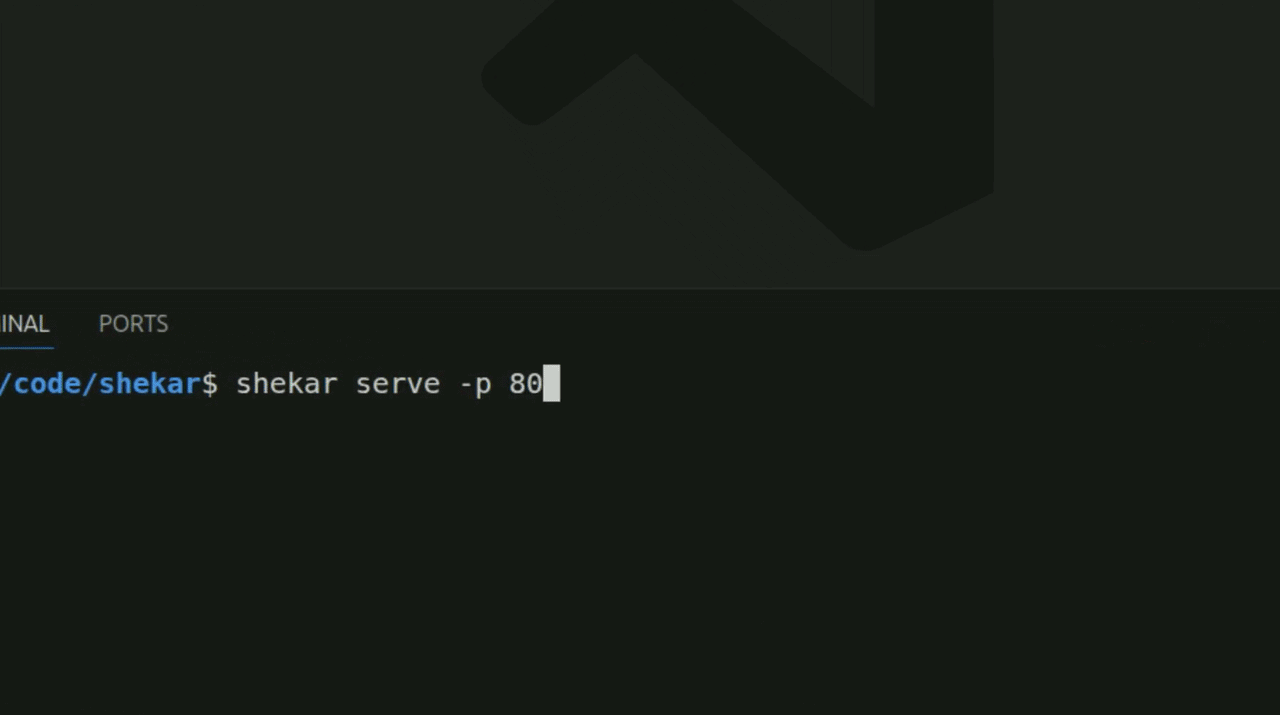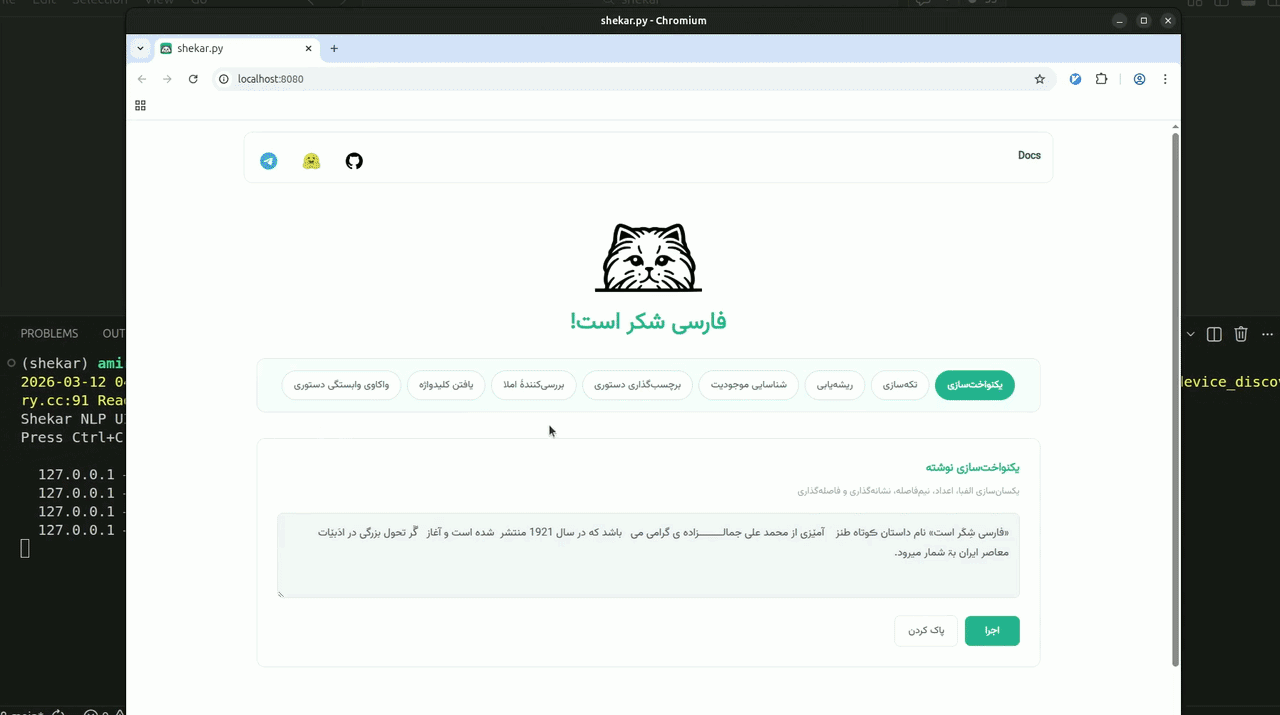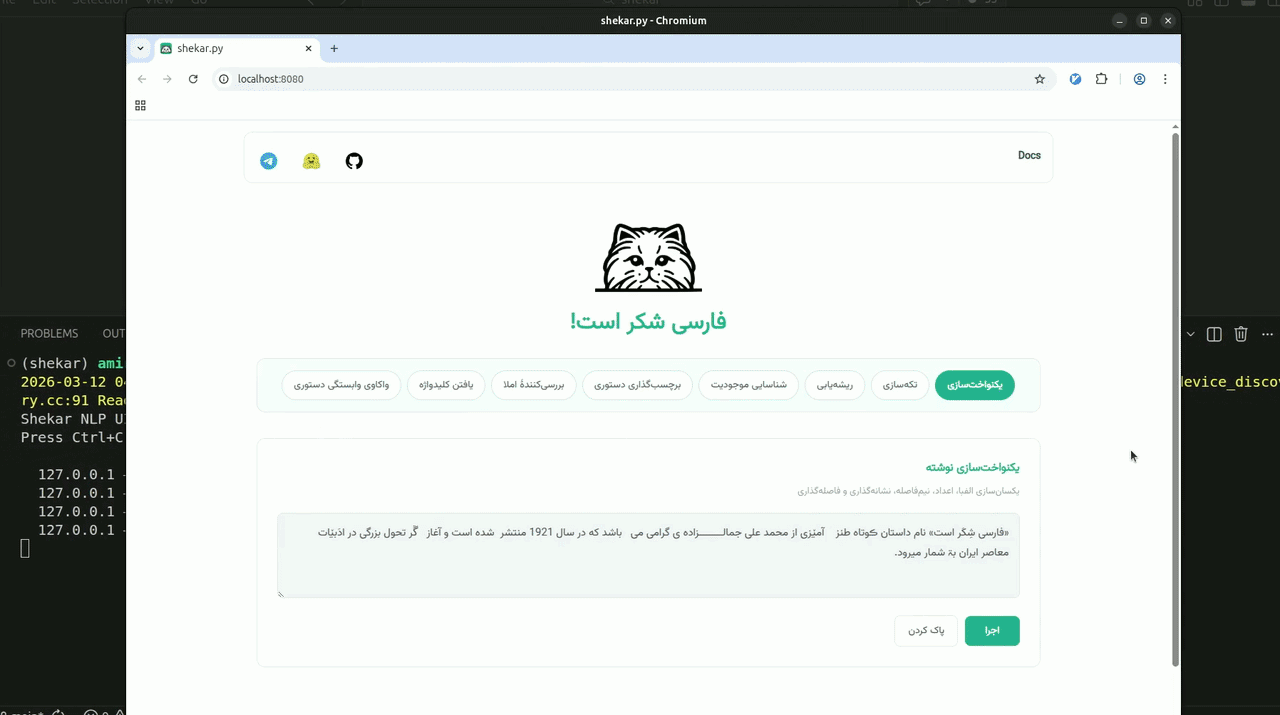
بارگیری مدلها
اگر Shekar Hub در دسترس نبود، میتوانید مدلها را بهصورت دستی بارگیری کرده و در فولدر cache به مسیر home/[username]/.shekar/ قرار دهید.
| نام مدل | پیوند بارگیری |
|---|---|
| FastText Embedding d100 | Download (50MB) |
| FastText Embedding d300 | Download (500MB) |
| SentenceEmbedding | Download (60MB) |
| POS Tagger | Download (38MB) |
| NER | Download (38MB) |
| Dependency Parser | Download (36MB) |
| AlbertTokenizer | Download (2MB) |