Overview






Simplifying Persian NLP for Modern Applications
Shekar (meaning 'sugar' in Persian) is a Python library for Persian natural language processing, named after the influential satirical story "فارسی شکر است" (Persian is Sugar) published in 1921 by Mohammad Ali Jamalzadeh. The story became a cornerstone of Iran's literary renaissance, advocating for accessible yet eloquent expression. Shekar embodies this philosophy in its design and development.
Table of Contents
- Installation
- CPU Installation (All Platforms)
- GPU Acceleration (NVIDIA CUDA)
- Preprocessing
- Normalizer
- Batch Processing
- Decorator Support
- Customization
- Using Pipelines
- Tokenization
- WordTokenizer
- SentenceTokenizer
- Embeddings
- Word Embeddings
- Sentence Embeddings
- Stemming
- Lemmatization
- Part-of-Speech Tagging
- Named Entity Recognition (NER)
- Sentiment Analysis
- Keyword Extraction
- Spell Checking
- WordCloud
- Command-Line Interface (CLI)
- Commands
- Download Models
Installation
You can install Shekar with pip. By default, the CPU runtime of ONNX is included, which works on all platforms.
CPU Installation (All Platforms)
This works on Windows, Linux, and macOS (including Apple Silicon M1/M2/M3).
GPU Acceleration (NVIDIA CUDA)
If you have an NVIDIA GPU and want hardware acceleration, you need to replace the CPU runtime with the GPU version.
Prerequisites
- NVIDIA GPU with CUDA support
- Appropriate CUDA Toolkit installed
- Compatible NVIDIA drivers
Preprocessing
![]()
![]()
Normalizer
The built-in Normalizer class provides a ready-to-use pipeline that combines the most common filters and normalization steps, offering a default configuration that covers the majority of use cases.
from shekar import Normalizer
normalizer = Normalizer()
text = "«فارسی شِکَر است» نام داستان ڪوتاه طنز آمێزی از محمد علی جمالــــــــزاده ی گرامی می باشد که در سال 1921 منتشر شده است و آغاز ڱر تحول بزرگی در ادَبێات معاصر ایران 🇮🇷 بۃ شمار میرود."
print(normalizer(text))
«فارسی شکر است» نام داستان کوتاه طنزآمیزی از محمدعلی جمالزادهی گرامی میباشد که در سال ۱۹۲۱ منتشر شدهاست و آغازگر تحول بزرگی در ادبیات معاصر ایران به شمار میرود.
Batch Processing
Both Normalizer and Pipeline support memory-efficient batch processing:
texts = [
"پرندههای 🐔 قفسی، عادت دارن به بیکسی!",
"تو را من چشم👀 در راهم!"
]
outputs = normalizer.fit_transform(texts)
print(list(outputs))
Decorator Support
Use .on_args(...) to apply the pipeline to specific function arguments:
@normalizer.on_args(["text"])
def process_text(text):
return text
print(process_text("تو را من چشم👀 در راهم!"))
Customization
For advanced customization, Shekar offers a modular and composable framework for text preprocessing. It includes components such as normalizers and maskers, which can be applied individually or flexibly combined using the Pipeline class with the | operator.
Component Overview
Normalizers
| Component | Aliases | Description | |------------|----------|-------------| | `AlphabetNormalizer` | `NormalizeAlphabets` | Converts Arabic characters to Persian equivalents | | `ArabicUnicodeNormalizer` | `NormalizeArabicUnicodes` | Replaces Arabic presentation forms (e.g., ﷽) with Persian equivalents | | `DigitNormalizer` | `NormalizeDigits` | Converts English/Arabic digits to Persian | | `PunctuationNormalizer` | `NormalizePunctuations` | Standardizes punctuation symbols | | `RepeatedLetterNormalizer` | `NormalizeRepeatedLetters` | Normalizes words with repeated letters (e.g., “سسسلام” → “سلام”) | | `SpacingNormalizer` | `NormalizeSpacings` | Corrects spacings in Persian text by fixing misplaced spaces, missing zero-width non-joiners (ZWNJ), and incorrect spacing around punctuation and affixes | | `YaNormalizer` | `NormalizeYas` | Normalizes Persian “یـا” in accordance with either the official standard (“standard”) or colloquial (“joda”) style |Maskers
| Component | Aliases | Description | |------------|----------|-------------| | `DiacriticMasker` | `DiacriticRemover`, `RemoveDiacritics`, `MaskDiacritics` | Removes or masks Persian/Arabic diacritics | | `DigitMasker` | `DigitRemover`, `RemoveDigits`, `MaskDigits` | Removes or masks all digit characters | | `EmojiMasker` | `EmojiRemover`, `RemoveEmojis`, `MaskEmojis` | Removes or masks emojis | | `EmailMasker` | `EmailRemover`, `RemoveEmails`, `MaskEmails` | Masks or removes email addresses | | `HashtagMasker` | `HashtagRemover`, `RemoveHashtags`, `MaskHashtags` | Masks or removes hashtags | | `HTMLTagMasker` | `HTMLTagRemover`, `RemoveHTMLTags`, `MaskHTMLTags` | Removes HTML tags while retaining content | | `MentionMasker` | `MentionRemover`, `RemoveMentions`, `MaskMentions` | Masks or removes @mentions | | `NonPersianLetterMasker` | `NonPersianRemover`, `RemoveNonPersianLetters`, `MaskNonPersianLetters` | Masks or removes all non-Persian letters (optionally keeps English) | | `OffensiveWordMasker` | `OffensiveWordRemover`, `RemoveOffensiveWords`, `MaskOffensiveWords` | Masks or removes Persian offensive words using a predefined or custom list | | `PunctuationMasker` | `PunctuationRemover`, `RemovePunctuations`, `MaskPunctuations` | Removes or masks punctuation characters | | `StopWordMasker` | `StopWordRemover`, `RemoveStopWords`, `MaskStopWords` | Masks or removes frequent Persian stopwords | | `URLMasker` | `URLRemover`, `RemoveURLs`, `MaskURLs` | Masks or removes URLs |Using Pipelines
You can combine any of the preprocessing components using the | operator:
from shekar.preprocessing import EmojiRemover, PunctuationRemover
text = "ز ایران دلش یاد کرد و بسوخت! 🌍🇮🇷"
pipeline = EmojiRemover() | PunctuationRemover()
output = pipeline(text)
print(output)
Tokenization
WordTokenizer
The WordTokenizer class in Shekar is a simple, rule-based tokenizer for Persian that splits text based on punctuation and whitespace using Unicode-aware regular expressions.
from shekar import WordTokenizer
tokenizer = WordTokenizer()
text = "چه سیبهای قشنگی! حیات نشئهٔ تنهایی است."
tokens = list(tokenizer(text))
print(tokens)
SentenceTokenizer
The SentenceTokenizer class is designed to split a given text into individual sentences. This class is particularly useful in natural language processing tasks where understanding the structure and meaning of sentences is important. The SentenceTokenizer class can handle various punctuation marks and language-specific rules to accurately identify sentence boundaries.
Below is an example of how to use the SentenceTokenizer:
from shekar.tokenizers import SentenceTokenizer
text = "هدف ما کمک به یکدیگر است! ما میتوانیم با هم کار کنیم."
tokenizer = SentenceTokenizer()
sentences = tokenizer(text)
for sentence in sentences:
print(sentence)
Embeddings
![]()
![]()
Shekar offers two main embedding classes:
WordEmbedder: Provides static word embeddings using pre-trained FastText models.SentenceEmbedder: Provides contextual embeddings using a fine-tuned ALBERT model.
Both classes share a consistent interface:
embed(text)returns a NumPy vector.transform(text)is an alias forembed(text)to integrate with pipelines.
Word Embeddings
WordEmbedder supports two static FastText models:
fasttext-d100: A 100-dimensional CBOW model trained on Persian Wikipedia.fasttext-d300: A 300-dimensional CBOW model trained on the large-scale Naab dataset.
Note: The word embeddings are static due to Gensim’s outdated dependencies, which can lead to compatibility issues. To ensure stability, the embeddings are stored as pre-computed vectors.
from shekar.embeddings import WordEmbedder
embedder = WordEmbedder(model="fasttext-d100")
embedding = embedder("کتاب")
print(embedding.shape)
similar_words = embedder.most_similar("کتاب", top_n=5)
print(similar_words)
Sentence Embeddings
SentenceEmbedder uses an ALBERT model trained with Masked Language Modeling (MLM) on the Naab dataset to generate high-quality contextual embeddings.
The resulting embeddings are 768-dimensional vectors representing the semantic meaning of entire phrases or sentences.
from shekar.embeddings import SentenceEmbedder
embedder = SentenceEmbedder(model="albert")
sentence = "کتابها دریچهای به جهان دانش هستند."
embedding = embedder(sentence)
print(embedding.shape) # (768,)
Stemming
The Stemmer is a lightweight, rule-based reducer for Persian word forms. It trims common suffixes while respecting Persian orthography and Zero Width Non-Joiner usage. The goal is to produce stable stems for search, indexing, and simple text analysis without requiring a full morphological analyzer.
from shekar import Stemmer
stemmer = Stemmer()
print(stemmer("نوهام"))
print(stemmer("کتابها"))
print(stemmer("خانههایی"))
Lemmatization
The Lemmatizer maps Persian words to their base dictionary form. Unlike stemming, which only trims affixes, lemmatization uses explicit verb conjugation rules, vocabulary lookups, and a stemmer fallback to ensure valid lemmas. This makes it more accurate for tasks like part-of-speech tagging, text normalization, and linguistic analysis where the canonical form of a word is required.
from shekar import Lemmatizer
lemmatizer = Lemmatizer()
print(lemmatizer("رفتند"))
print(lemmatizer("کتابها"))
print(lemmatizer("خانههایی"))
print(lemmatizer("گفته بودهایم"))
Part-of-Speech Tagging
![]()
![]()
The POSTagger class provides part-of-speech tagging for Persian text using a transformer-based model (default: ALBERT). It returns one tag per word based on Universal POS tags (following the Universal Dependencies standard).
Example usage:
from shekar import POSTagger
pos_tagger = POSTagger()
text = "نوروز، جشن سال نو ایرانی، بیش از سه هزار سال قدمت دارد و در کشورهای مختلف جشن گرفته میشود."
result = pos_tagger(text)
for word, tag in result:
print(f"{word}: {tag}")
نوروز: PROPN
،: PUNCT
جشن: NOUN
سال: NOUN
نو: ADJ
ایرانی: ADJ
،: PUNCT
بیش: ADJ
از: ADP
سه: NUM
هزار: NUM
سال: NOUN
قدمت: NOUN
دارد: VERB
و: CCONJ
در: ADP
کشورهای: NOUN
مختلف: ADJ
جشن: NOUN
گرفته: VERB
میشود: VERB
.: PUNCT
Named Entity Recognition (NER)
![]()
![]()
The NER module in Shekar offers a fast, quantized Named Entity Recognition pipeline using a fine-tuned ALBERT model in ONNX format. It detects common Persian entities such as persons, locations, organizations, and dates. This model is designed for efficient inference and can be easily combined with other preprocessing steps.
Example usage:
from shekar import NER
from shekar import Normalizer
input_text = (
"شاهرخ مسکوب به سالِ ۱۳۰۴ در بابل زاده شد و دوره ابتدایی را در تهران و در مدرسه علمیه پشت "
"مسجد سپهسالار گذراند. از کلاس پنجم ابتدایی مطالعه رمان و آثار ادبی را شروع کرد. از همان زمان "
"در دبیرستان ادب اصفهان ادامه تحصیل داد. پس از پایان تحصیلات دبیرستان در سال ۱۳۲۴ از اصفهان به تهران رفت و "
"در رشته حقوق دانشگاه تهران مشغول به تحصیل شد."
)
normalizer = Normalizer()
normalized_text = normalizer(input_text)
albert_ner = NER()
entities = albert_ner(normalized_text)
for text, label in entities:
print(f"{text} → {label}")
شاهرخ مسکوب → PER
سال ۱۳۰۴ → DAT
بابل → LOC
دوره ابتدایی → DAT
تهران → LOC
مدرسه علمیه → LOC
مسجد سپهسالار → LOC
دبیرستان ادب اصفهان → LOC
در سال ۱۳۲۴ → DAT
اصفهان → LOC
تهران → LOC
دانشگاه تهران → ORG
فرانسه → LOC
You can seamlessly chain NER with other components using the | operator:
ner_pipeline = normalizer | albert_ner
entities = ner_pipeline(input_text)
for text, label in entities:
print(f"{text} → {label}")
This chaining enables clean and readable code, letting you build custom NLP flows with preprocessing and tagging in one pass.
Sentiment Analysis
The SentimentClassifier module enables automatic sentiment analysis of Persian text using transformer-based models. It currently supports the AlbertBinarySentimentClassifier, a lightweight ALBERT model fine-tuned on Snapfood dataset to classify text as positive or negative, returning both the predicted label and its confidence score.
Example usage:
from shekar import SentimentClassifier
sentiment_classifier = SentimentClassifier()
print(sentiment_classifier("سریال قصههای مجید عالی بود!"))
print(sentiment_classifier("فیلم ۳۰۰ افتضاح بود!"))
Keyword Extraction
![]()
![]()
The shekar.keyword_extraction module provides tools for automatically identifying and extracting key terms and phrases from Persian text. These algorithms help identify the most important concepts and topics within documents.
from shekar import KeywordExtractor
extractor = KeywordExtractor(max_length=2, top_n=10)
input_text = (
"زبان فارسی یکی از زبانهای مهم منطقه و جهان است که تاریخچهای کهن دارد. "
"زبان فارسی با داشتن ادبیاتی غنی و شاعرانی برجسته، نقشی بیبدیل در گسترش فرهنگ ایرانی ایفا کرده است. "
"از دوران فردوسی و شاهنامه تا دوران معاصر، زبان فارسی همواره ابزار بیان اندیشه، احساس و هنر بوده است. "
)
keywords = extractor(input_text)
for kw in keywords:
print(kw)
Spell Checking
The SpellChecker class provides simple and effective spelling correction for Persian text. It can automatically detect and fix common errors such as extra characters, spacing mistakes, or misspelled words. You can use it directly as a callable on a sentence to clean up the text, or call suggest() to get a ranked list of correction candidates for a single word.
from shekar import SpellChecker
spell_checker = SpellChecker()
print(spell_checker("سسلام بر ششما ددوست من"))
print(spell_checker.suggest("درود"))
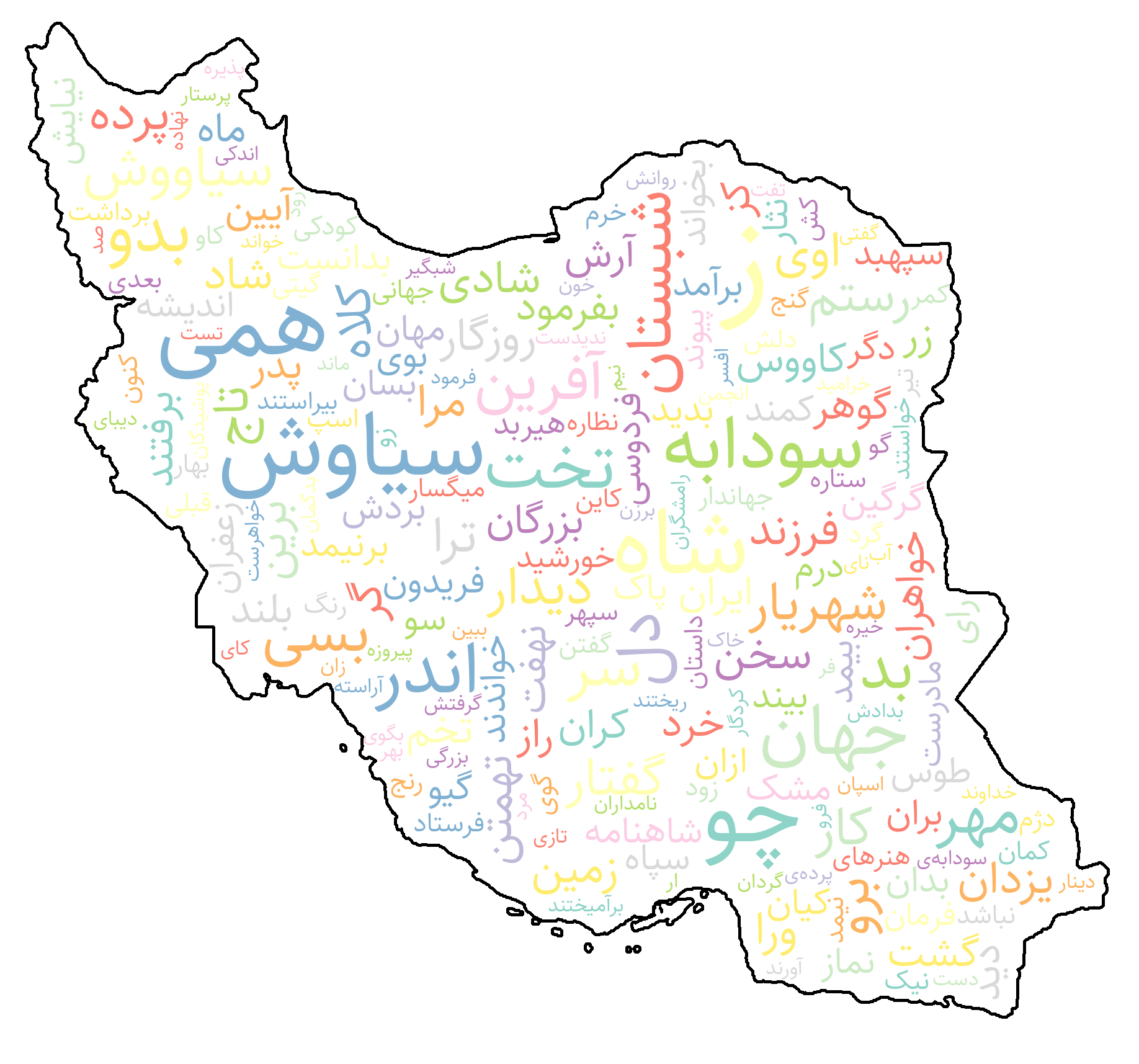
WordCloud
![]()
![]()
The WordCloud class offers an easy way to create visually rich Persian word clouds. It supports reshaping and right-to-left rendering, Persian fonts, color maps, and custom shape masks for accurate and elegant visualization of word frequencies.
import requests
from collections import Counter
from shekar import WordCloud
from shekar import WordTokenizer
from shekar.preprocessing import (
HTMLTagRemover,
PunctuationRemover,
StopWordRemover,
NonPersianRemover,
)
preprocessing_pipeline = HTMLTagRemover() | PunctuationRemover() | StopWordRemover() | NonPersianRemover()
url = f"https://ganjoor.net/ferdousi/shahname/siavosh/sh9"
response = requests.get(url)
html_content = response.text
clean_text = preprocessing_pipeline(html_content)
word_tokenizer = WordTokenizer()
tokens = word_tokenizer(clean_text)
word_freqs = Counter(tokens)
wordCloud = WordCloud(
mask="Iran",
width=1000,
height=500,
max_font_size=220,
min_font_size=5,
bg_color="white",
contour_color="black",
contour_width=3,
color_map="Set2",
)
# if shows disconnect words, try again with bidi_reshape=True
image = wordCloud.generate(word_freqs, bidi_reshape=False)
image.show()
Command-Line Interface (CLI)
Shekar includes a command-line interface (CLI) for quick text processing and visualization.
You can normalize Persian text or generate wordclouds directly from files or inline strings.
Usage
Commands
normalize
Normalize Persian text by standardizing spacing, characters, and diacritics.
Works with files or inline text.
Options
-i, --inputPath to an input text file-o, --outputPath to save normalized text. If not provided, results are printed to stdout-t, --textInline text instead of a file--encodingForce a specific input file encoding--progressShow progress bar (enabled by default)
Examples
# Normalize a text file and save output
shekar normalize -i ./corpus.txt -o ./normalized_corpus.txt
# Normalize inline text
shekar normalize -t "درود پرودگار بر ایران و ایرانی"
wordcloud
Generate a wordcloud image (PNG) from Persian text, either from a file or inline.
Preprocessing automatically removes punctuation, diacritics, stopwords, non-Persian characters, and normalizes spacing.
Options
-i, --inputInput text file-t, --textInline text instead of a file-o, --output(required) Path to output PNG file--bidiApply bidi reshaping for correct rendering of Persian text (default:False)--maskShape mask (Iran,Heart,Bulb,Cat,Cloud,Head) or custom image path--fontFont to use (sahel,parastoo, or custom TTF path)--widthImage width in pixels (default: 1000)--heightImage height in pixels (default: 500)--bg-colorBackground color (default: white)--contour-colorOutline color (default: black)--contour-widthOutline thickness (default: 3)--color-mapMatplotlib colormap for words (default: Set2)--min-font-sizeMinimum font size (default: 5)--max-font-sizeMaximum font size (default: 220)
Examples
# Generate a wordcloud from a text file
shekar wordcloud -i ./corpus.txt -o ./word_cloud.png
# Generate a wordcloud from inline text with a custom mask
shekar wordcloud -t "درود پرودگار بر ایران و ایرانی" -o ./word_cloud.png --mask Heart
Note: If the letters in the generated wordcloud appear separated, use the --bidi option to enable proper Persian text shaping.
Download Models
If Shekar Hub is unavailable, you can manually download the models and place them in the cache directory at home/[username]/.shekar/
| Model Name | Download Link |
|---|---|
| FastText Embedding d100 | Download (50MB) |
| FastText Embedding d300 | Download (500MB) |
| SentenceEmbedding | Download (60MB) |
| POS Tagger | Download (38MB) |
| NER | Download (38MB) |
| AlbertTokenizer | Download (2MB) |